
现代同步辐射光源就像一台不知疲倦的高速摄像机。 做一次全场谱学显微实验,短短 15 分钟就能产生 2048 x 2048 个像素点的 XANES 光谱。每一个像素点都包含着丰富的化学信息。 面对这几百万条曲线,如何提取出关键的构效关系?答案是:数据科学(Data Science)。
在研究 LCO 颗粒的衰减机制时,Zhang 等人没有盯着某一个颗粒看,而是扫描了数百个颗粒。
Mao 等人在研究 NMC-622 时,采用了一种更聪明的混合策略:
在做纳米 CT(Nano-tomography)时,最头疼的是如何把粘在一起的颗粒分开(Segmentation),特别是当颗粒已经碎成好几块的时候。 传统的**分水岭算法(Watershed)**经常会把一个碎裂的颗粒误判成好几个小颗粒。 Jiang 等人训练了一个深度学习模型:
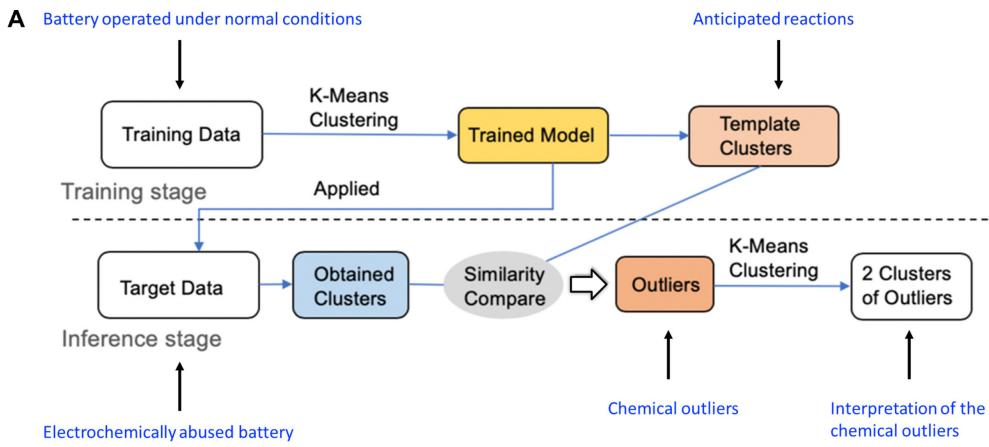 图1. 混合机器学习算法流程图
通过“先聚类、后分类、再聚类”的策略,从海量光谱数据中自动识别出代表电池老化的化学“离群点”。
图1. 混合机器学习算法流程图
通过“先聚类、后分类、再聚类”的策略,从海量光谱数据中自动识别出代表电池老化的化学“离群点”。
别让扣电数据掩盖材料的真实性能。 我们提供从粉末到圆柱全电池的一站式验证服务,用头部电池厂的标准(Enterprise Standards)为您提供"通行证"级别的数据报告。
欢迎联系我们 19939716636












 首页
首页
 检测领域
检测领域
 服务项目
服务项目
 咨询报价
咨询报价
